AI Interviewers, Qualitative Literacy, and “Big Dick” Data
In the summer of 2023, a wonderful team of PhD interns and I decided to test whether AI could do interviews. We ended up writing one of the first papers on the topic.
Now, Anthropic has scaled the approach to more than 80,000 people around the world.
It’s a wild time for computational social scientists, so I wanted to reflect a little bit on what my team tried to do and why it fell far short of real interviews. I'll also talk about where more recent papers have gotten better results, and the promise I nevertheless see in Anthropic’s use of the approach.
Quality in Qualitative Research
I originally pitched the research project as asking whether AI could do interviews. Alejandro Cuevas drove the implementation and became the paper’s lead author. From day 1, he and I and the rest of the team tried not to take ourselves too seriously.

Yes, the tech was cool and promising, but it was still the GPT 3.5 days and it was obviously far from where it would be. So, we set up our AI to ask questions about AI. We wanted it to be a little silly, and we also wanted a little side jab on positionality: it is well established that interviewer identity matters, so if we were going to make our interviewer an AI, we decided, we might as well go all in.
We were also concerned about being assholes. Qualitative research is already under-resourced and under-valued. Empiricists dominate the top journals and funding, but of course having good hypotheses to test has always required what my epidemiologist friends call “shoe-leather” work – exploratory and deep observation in the field.
A key challenge is that it’s hard to agree on what qualitative research is, and what it is for. In fact this has been the subject of nasty and internecine battles. You could spend a whole career on the problem, and many people have.
For us, what happened was that when we got our results back, we had the nagging sense that the responses were not very good but we couldn't say why. We had a lot of responses. The responses were very detailed. They did fine on previous tests for ML-driven interviewing in the HCI literature. But then, so did our control setup, in which the AI just asked hard-coded probes.

Early on, we met with the brilliant Harvard political scientist Danielle Allen to ask for advice. She pointed us to Mario Small and Jessica Calarco’s framework for evaluating qualitative research, Qualitative Literacy. When I finally sat down to read it, it was a breakthrough. Suddenly I had words for precisely what it was that felt so off. (My interns can tell you that I became somewhat insufferable about it.)
Small and Calarco document five principles of great qualitative research:
- Cognitive empathy – the extent to which the researcher understands the participant’s perspective on their own terms.
- Palpability - the concreteness and specificity of the evidence, meaning quotes and insights bring the reader closer to the participants' real lived experiences.
- Follow-up - the responsiveness of the researcher to the new and unanticipated questions that emerge in the field.
- Heterogeneity - the degree to which the research captures the breadth and diversity of the people depicted and their perspectives.
- Self-awareness - recognition of the effect the researcher’s presence and perspective has on the participants and the nature of the research.
All of these principles are really meant for evaluating an ethnographic study as a whole, across sites and over time, but even if you just apply them to the single snippet above you can already start to see a lot of the problem. The participant sounds thoughtful, and they are, but they’re not actually talking about their own situation. The interviewer bot is not plumbing the participant’s internal depths. It is not pushing on why e.g. emotional harm is such a concern to this particular person. The quotes are broad generalities.
We write in the paper that this could maybe be fixed by a better model, but it could also be mechanical. Palpability and cognitive empathy is not where the mass of the textual probability distribution finds itself. AI’s love for the banal and the general seems hard-coded. Getting past it will require real technical break-throughs – memory, systems for abductive reasoning – not just a raw model dressed in a “you are a brilliant researcher” prompt trench coat.
First, Last, and Useful
A wise person once told me that, in research, you want your paper to be the first or the last. When we were doing our work in the summer of 2023 we were among the first. This was cool, but it also meant there was nothing else to go by.
I’m proud of the work we did in introducing Small and Calarco to HCI and quant audiences who might have otherwise missed it, but this was GPT 3.5 and if you read the paper you will see that we are developing basic prompt benchmarking ideas from scratch. We had to figure out every piece of the tooling, research design, and theoretical framework from scratch. It was early days!
The space is vibrant now, with tons of excellent papers. Chopra and Haaland posted their preprint around the same time as ours; delightfully, their latest version finds saturation not far from where qualitative scholars expected (N = 25!). Another great one is by Geiecke and Jaravel, forthcoming in the Review of Economic Studies. They did not have AI ask about AI but instead decided to go straight for “meaning in life” and several other hard-hitting topics. A relatively simple LLM setup with probing capabilities was enough, they find, to surface new insights about what it is that really matters to people. (Owning a pet, for example, came up as frequently as did religion).
Like us, they draw on Small and Calarco for what they count as quality. Unlike us, they worked with a bunch of trained sociologists to have both humans and AI run the interviews, and then hire other sociologists to evaluate the quality differences between the two. They find that an AI interview conducted with voice performs comparably to human experts in face-to-face interviews and outperforms human experts interviewing via text interfaces.
This is the kind of AI work that always gives me a small existential crisis.
I do think that part of what we are all showing is how impoverished a lot of interviewing has become. It’s not uncommon for teams to write one highly structured protocol and then ship it out to a handful of underpaid RAs, which is far from Small and Calarco’s platonic ideal. But the reality is that this is a well-designed and thorough study, which means you have to take the results seriously.
I will say that if I was a graduate student looking where to go next, I would be so excited by the many meaty open questions in this space. If you can collect all this qualitative data, then how do you analyze it? How do you visualize it? Can you incorporate qualitative feedback into the visualization and dashboard tooling that runs so much of the world’s great technology companies? How do you do that in ways that respect cognitive empathy and palpability while keeping the insights actionable? There are still so many opportunities for firsts.
Of course whether you are first or last matters far less than whether your work is useful. The dream is to get out of academic paper-space entirely and do something that industry or government or civil society picks up.
Which brings us to the big Anthropic drop.
The world’s largest qualitative study?
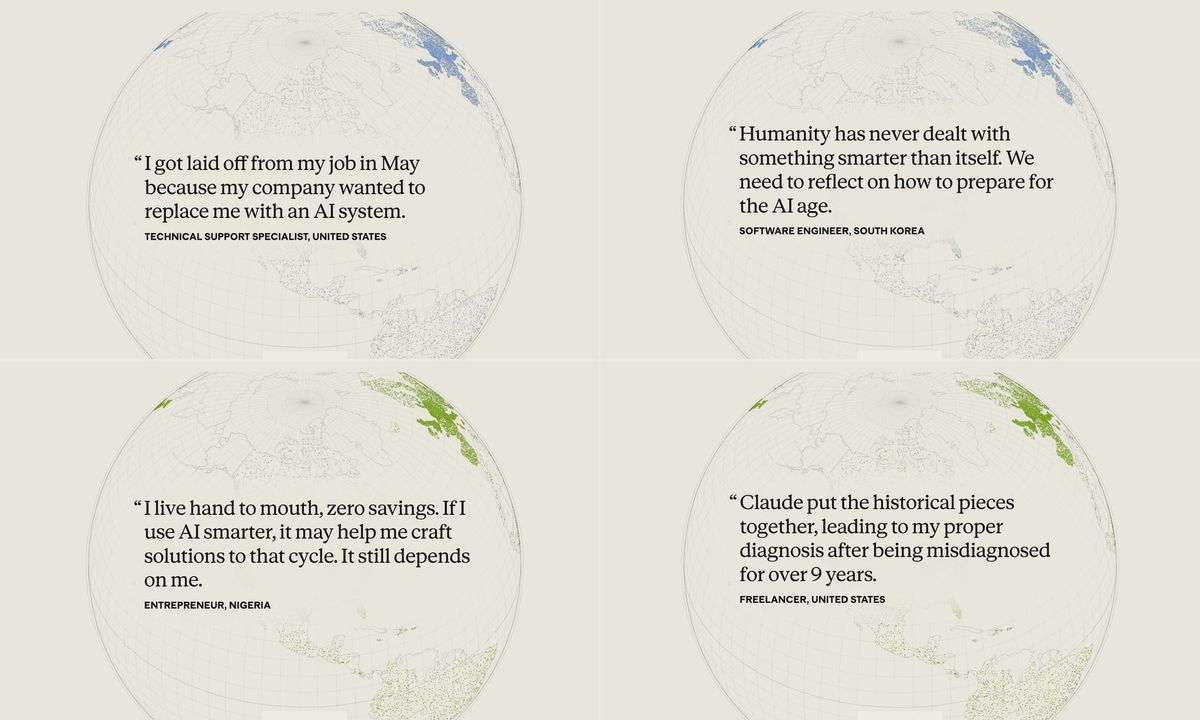
In December, Anthropic invited everyone with a Claude account to “sit down” with an AI interviewer. 80,508 account-holders took them up on the offer. As in our work and the Geiecke and Jaravel, the setup is a simple approximation of a semi-structured interview protocol, with a core set of research questions followed by dynamic and adaptive probes. The team then uses more AI to classify the responses and pull out representative quotes.
Graded on scale and timeliness and coverage, this is excellent work. The tensions they highlight – between emotional support and dependence, or better decision-making and unreliability – offer a real product roadmap. The comparison across geographies also shows viscerally how that roadmap might differ by place.
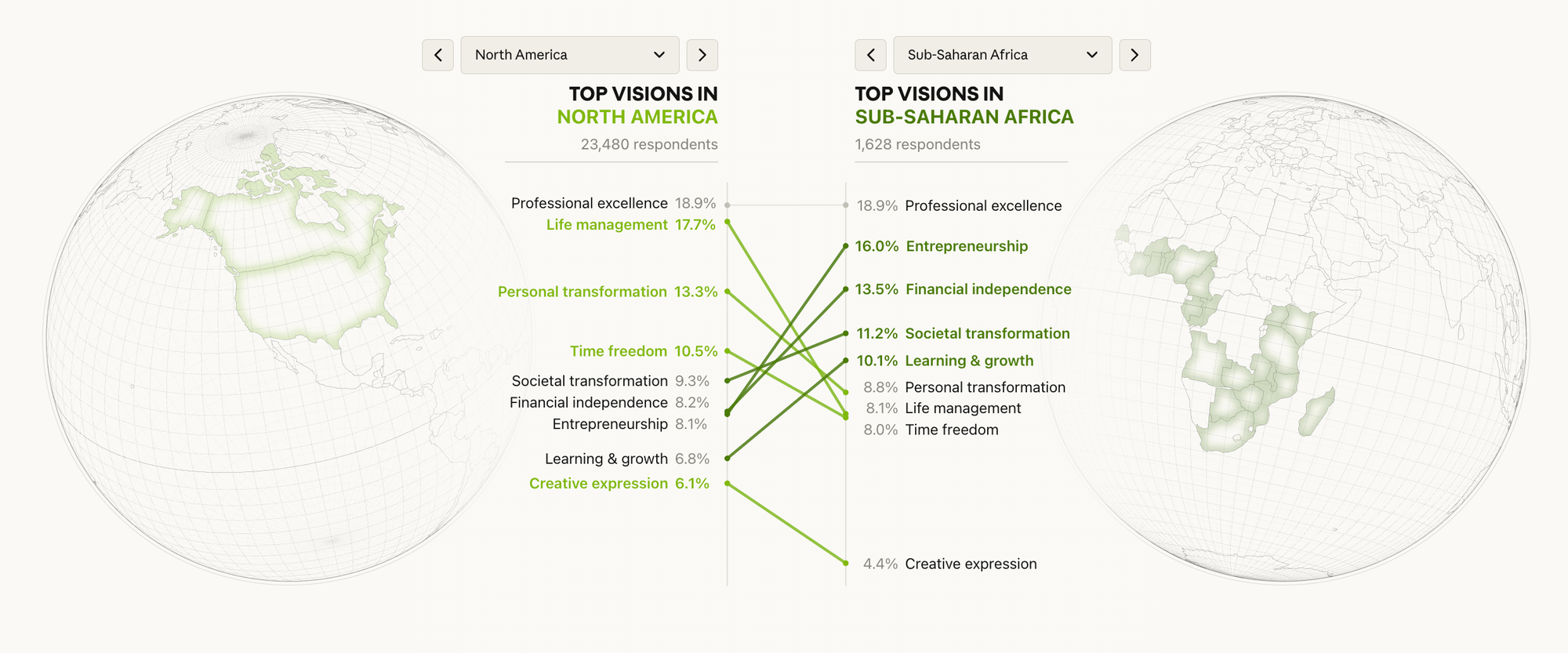
But graded on cognitive empathy, palpability, self-awareness, heterogeneity, and follow-up, the results are more mixed. The biggest one is of course self-awareness: this is a study by Claude, about Claude, with self-selected Claude users.
Throughout, Anthropic makes the claim that this is the world’s largest qualitative study. I too have played the corporate tech PR game, so I respect this hustle. However: this is what Catherine D’ignazio and Lauren Klein, in Data Feminism, call big dick data, when people get into tiffs about size when of course what matters is how you use it.
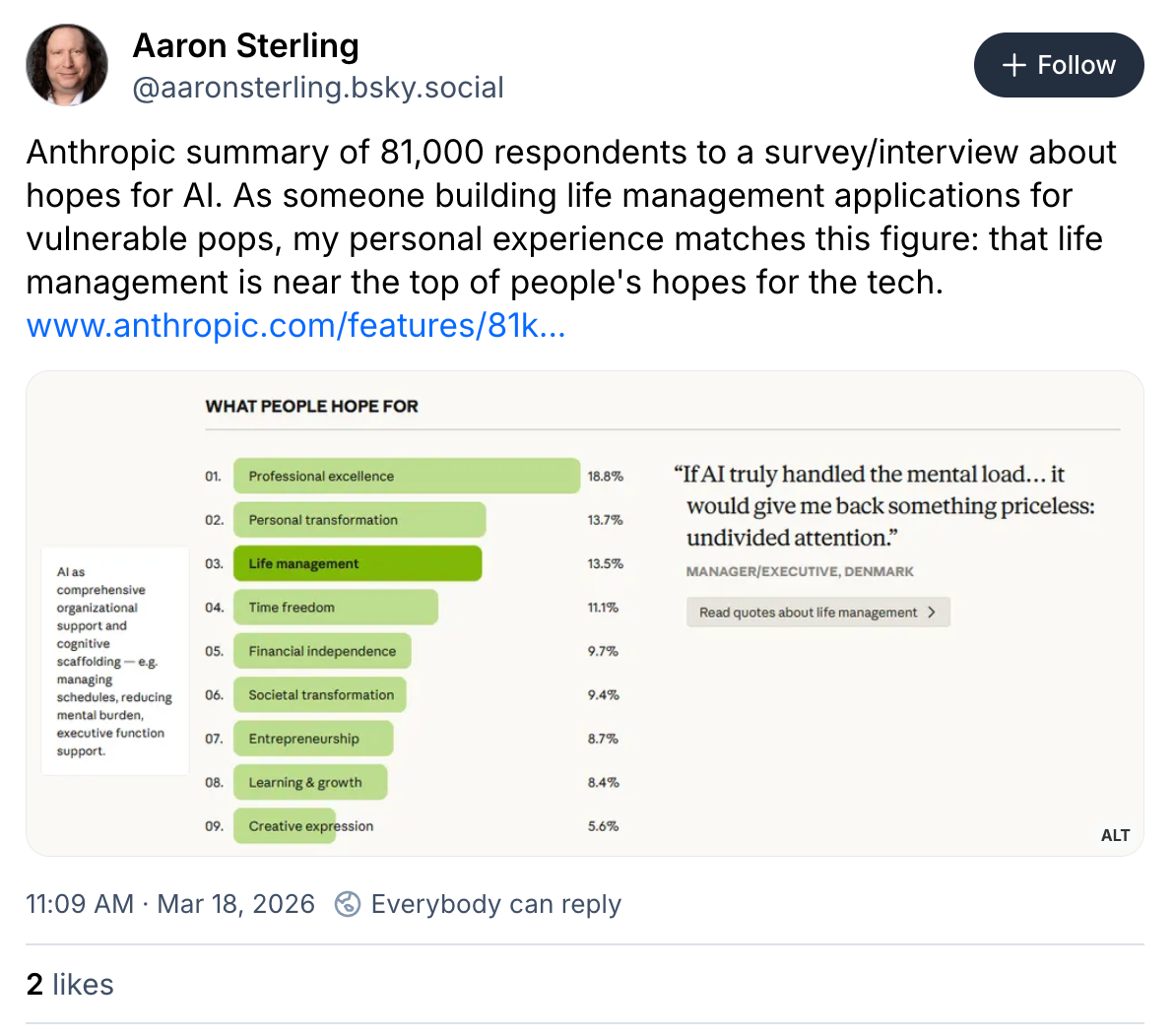
What I am impressed by with this method—whether it is an interview or a survey or something totally different—is less this study’s size than its breadth and diversity. They looked at people across 159 countries in 70 languages. This is not unprecedented for a corporate survey, or for user research on a global product. But they did it fast, and well, and if everyone did this with their products we could genuinely get much better products.
Where do we go from here?
I have always struggled with the relative poverty of so much of the data we collect quantitatively. The questions I can study with Likert Scales and diff-in-diffs feels so impoverished relative to what I can learn by reading Matthew Desmond or Katherine Boo.
AI-augmented, adaptive surveying is closer. But it’s also still nowhere close to what the world’s great listeners find when they embed deeply in a real place, time, and problem. We need a plurality of research methods, just like we need a plurality of perspectives shaping our tech.
Still, the core belief that shapes my own research is that everyone ought to have a voice in shaping the technologies that shape their lives. Changing what counts as data changes what data counts, and that is a major and needed change for the tech and for the world.
As always this article was written by me using only my human brain, without AI, though I used AI for factchecking, editing, and general moral support.

